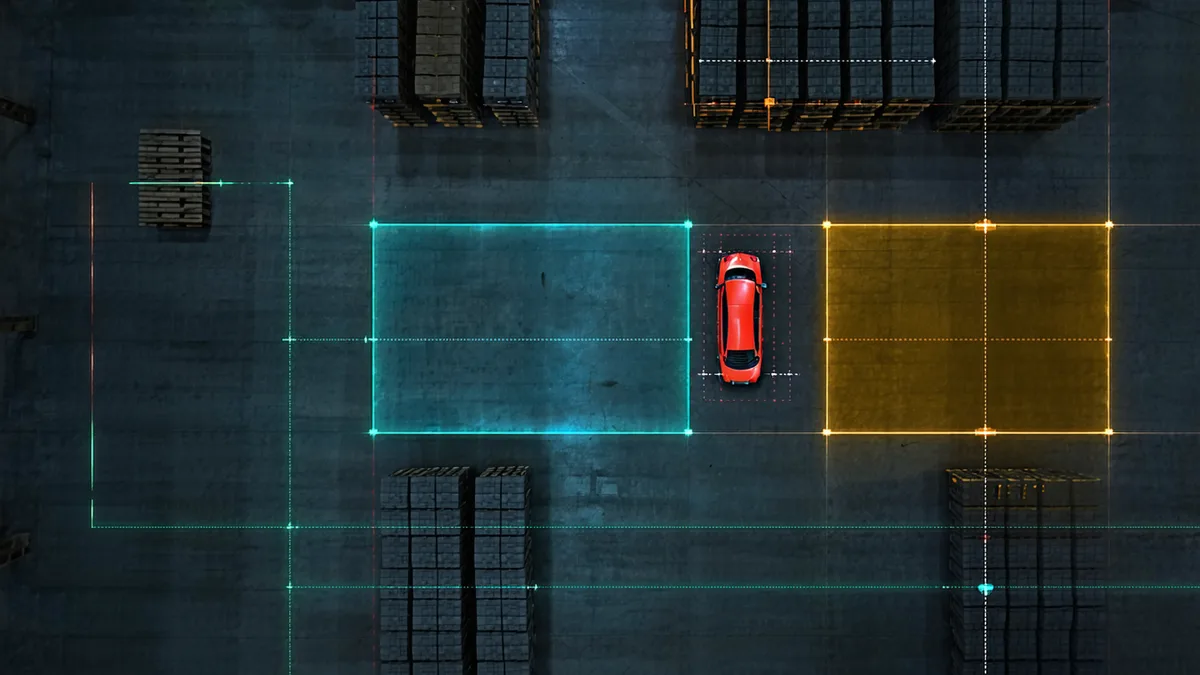
Developing perception software for AMRs presents a testing paradox: the environment that matters most for testing — a working warehouse with real forklifts, real human pickers, and real obstacle diversity — is also the environment least available during development. You can't park robots in a live facility to run regression tests. You can't reproduce the exact obstacle sequence that caused a misclassification last Tuesday without a lot of luck or a lot of planning.
We built a simulation harness that sidesteps this problem. It's not a full-physics warehouse simulator — those exist and are useful for different things. It's specifically a LiDAR bag file replay harness: a toolchain for recording real sensor data from field deployments and replaying it through the perception pipeline in a controlled, reproducible, instrumentable environment. Here's how it works and what we've learned using it.
The Architecture: Bag Replay as a Test Oracle
The core concept is straightforward. ROS 2 bag files (.mcap or the legacy .db3 format) capture raw topic data with timestamps. For our harness, we record the following topics during field runs:
/scan # 2D LiDAR scan (sensor_msgs/LaserScan)
/velodyne_points # 3D LiDAR point cloud (sensor_msgs/PointCloud2)
/odom # Odometry (nav_msgs/Odometry)
/tf # Transform tree (tf2_msgs/TFMessage)
/mvnt/perception/raw_detections # Our internal detection output
During replay, we feed the raw sensor topics (/scan, /velodyne_points) through the live perception pipeline while suppressing the recorded /mvnt/perception/raw_detections. The pipeline produces new detection output, which we diff against the ground-truth labels we've annotated on the recorded sequences.
The annotation step is where most of the human labor goes. We have a lightweight labeling tool built on RViz2 that lets us step through a bag file frame-by-frame and mark obstacle classifications — forklift, person, static-cart, unknown-low-profile — with temporal extent labels. An annotated bag file becomes a test case: replaying it through the updated pipeline and checking classification match rate and detection latency against the labels is fully automated.
What the Toolchain Actually Looks Like
A simplified version of our replay invocation:
ros2 bag play warehouse_run_2025_07_11.mcap \
--topics /scan /velodyne_points /odom /tf \
--rate 1.0 \
--start-offset 120.0 \
--duration 600.0 \
--ros-args --remap /clock:=/use_sim_time
# In a second terminal, launch the perception pipeline in sim-time mode:
ros2 launch mvnt_perception perception_stack.launch.py \
use_sim_time:=true \
output_bag:=/tmp/replay_output_$(date +%s).mcap
The use_sim_time:=true parameter is critical. All timing-sensitive components in the perception stack — our sliding-window obstacle tracker, the persistence scorer, the classification confidence decay — need to consume sim time from the bag replay, not wall clock time. Getting this wrong produces wildly incorrect persistence scores because the tracker thinks obstacles appeared and disappeared instantaneously.
After replay, we run a diff script that compares the output bag's /mvnt/perception/classified_obstacles topic against the ground-truth annotation file. The output is a per-class confusion matrix and a latency distribution for time-to-first-detection on each annotated obstacle instance.
What We Learned About Test Coverage Gaps
The most valuable thing the harness revealed wasn't classification accuracy — we had a reasonable handle on that from field reports. It was the edge cases we hadn't thought to test because we hadn't seen them fail in the field yet.
Sensor dropout sequences. We found that several of our bag files contained brief LiDAR dropout intervals — 80–200ms gaps where scan data was missing due to sensor buffer overrun or USB bandwidth contention. Our pipeline handled clean data well but produced phantom detections during recovery from dropouts, because the tracker was interpreting the resumed scan as a scene with new objects where previously there had been none. We hadn't tested this failure mode because we didn't think to inject dropout sequences. The real-world bag files surfaced it for us.
Near-field saturation zones. The Velodyne VLP-16 and similar 16-channel LiDARs have a minimum detection range of roughly 0.5–0.9m. Objects closer than that fall into the sensor's near-field saturation zone and produce spurious returns. In one warehouse facility with narrow aisle widths (~1.8m clear between rack faces), robots regularly passed close enough to rack uprights that the near-field saturation pattern was triggering our upright-detector — not as racks, but as "unknown low-profile objects moving alongside the robot." That was causing unnecessary confidence drops in adjacent detections. We identified and fixed this in simulation before it caused any field incidents.
Temporal labeling gaps in annotation. We discovered that our annotators were inconsistently handling the moment when an obstacle enters and exits the LiDAR field of view. The first and last few frames of an obstacle's presence in a scan sequence are sparse — partial point sets, low confidence — and annotators were sometimes marking these as "no obstacle" instead of "obstacle, low confidence." This was creating false training signal in our classification model. We built explicit handling for "entry/exit frames" in the annotation schema.
The Limits of Bag Replay Testing
We want to be direct about what this harness doesn't do well.
It doesn't test perception responses that depend on the robot's motion decisions. Bag replay is fundamentally open-loop: the robot in the recording followed one path, and the perception output we're testing was recorded from that path. If our updated pipeline would have caused the robot to stop earlier and approach a different angle, we can't test the resulting perception state from the bag — we'd need a closed-loop simulation for that.
It also doesn't give us diversity on rare obstacle classes. We might have 200 forklift sequences and 8 low-clearance autonomous tugger sequences. The classification model's performance on tuggers is harder to evaluate because we have fewer representative bag files. Generating synthetic LiDAR point clouds for rare obstacle types is possible — we've experimented with raycast simulation on CAD models — but synthetic data introduces its own distribution shift and we treat it cautiously.
For coverage of closed-loop behaviors and rare class diversity, we use Gazebo-based simulation with purpose-built obstacle actors. The bag replay harness complements that: it gives us regression coverage on real-world sensor characteristics that synthetic simulation environments get wrong (multipath returns, range noise distributions, dropout patterns), and it makes every field issue a reproducible test case for the regression suite.
Getting This Into a CI Pipeline
We run a subset of our annotated bag files in CI on every pull request: the five highest-traffic scenario types (general aisle, forklift zone, cross-aisle intersection, charging station approach, human-mixed zone) for a duration of 5 minutes each. Total CI runtime for the perception regression suite is about 18 minutes on the test runner, which is acceptable for pre-merge validation.
The field bag library currently has 47 annotated sequences covering 12 distinct facility types. We add new sequences whenever we encounter a field scenario that isn't represented in the existing set — typically after any incident that generates a classification report or after deploying at a new facility type. That keeps the test suite grounded in real conditions rather than drifting toward synthetic idealization.